Micro
Building Resilient and Fault Tolerant Applications with Micro
It’s been a little while since the last blog post but we’ve been hard at work on Micro and it’s definitely starting
to pay off. Let’s dive into it all now!
If you want to read up on the Micro toolkit first, check out the previous blog post here or if you would like to learn more about the concept of microservices look here.
It’s no secret that building distributed systems can be challenging. While we’ve solved a lot of problems as an industry along the way, we still go through cycles of rebuilding many of the building blocks. Whether it’s because of the move to the next level of abstraction, virtual machines to containers, adopting new languages, leveraging cloud based services or even this coming shift to microservices. There’s always something that seems to require us to relearn how to build performant and fault tolerant systems for the next wave of technology.
It’s a never ending battle between iteration and innovation but we need to do something to help alleviate a lot of the pains as the shift to Cloud, Containers and Microservices continues.
The Motivations
So why are we doing this? Why do we keep rebuilding the building blocks and why do we keep attempting to solve the same scale, fault tolerance and distributed systems problems?
The term that comes to mind are, “bigger, stronger, faster”, or perhaps even, “speed, scale, agility”. You’ll hear these a lot from C-level executives but the key takeaways are really that there’s always a need for us to build more performant and resilient systems.
In the early days of the internet, there were only thousands or maybe even hundreds of thousands of people coming online. Over time we saw that accelerate and we’re now into the order of billions. Billions of people and billions of devices. We’ve had to learn how to build systems for this.
For the older generation you may remember the C10K problem. I’m not sure where we are with this now but I think we’re talking about solving the issue of millions of concurrent connections if not more. The biggest technology players in the world really solved this a decade ago and have patterns for building systems at scale but the rest of us are still learning.
The likes of Amazon, Google and Microsoft now provide us with Cloud Computing platforms to leverage significant scale but we’re still trying to figure out how to write applications that can effectively leverage it. You’re hearing the terms container orchestration, microservices and cloud native a lot these days. The work is underway on a multitude of levels and it’s going to be a while before we as an industry have really nailed down the patterns and solutions needed moving forward.
A lot of companies are now helping with the question of, “how do I run my applications in a scalable and fault tolerant manner?”, but there’s still very few helping with the more important question…
How do I actually write applications in a scalable and fault tolerant manner?
Micro looks to address these problems by focusing on the key software development requirements for microservices. We’ll run through some of what can help you build resilient and fault tolerant applications now, starting with the client side.
The Client
The client is a building block for making requests in go-micro. If you’ve built microservices or SOA architectures before then you’ll know that a significant portion of time and execution is spent on calling other services for relevant information.
Whereas in a monolithic application the focus on mainly on serving content, in a microservices world it’s more about retrieving or publishing content.
Here’s a cut down version of the go-micro client interface with the three most important methods; Call, Publish and Stream.
type Client interface {
Call(ctx context.Context, req Request, rsp interface{}, opts ...CallOption) error
Publish(ctx context.Context, p Publication, opts ...PublishOption) error
Stream(ctx context.Context, req Request, opts ...CallOption) (Streamer, error)
}
type Request interface {
Service() string
Method() string
ContentType() string
Request() interface{}
Stream() bool
}
Call and Stream are used to make synchronous requests. Call returns a single result whereas Stream is a bidirectional streaming connection maintained with another service, over which messages can be sent back and forth. Publish is used to publish asynchronous messages via the broker but we’re not going to discuss that today.
How the client works behind the scenes was addressed in a couple of previous blog posts which you can find here and here. Check those out if you want to learn about the details.
We’ll just briefly mention some important internal details.
The client deals with the RPC layer while leveraging the broker, codec, registry, selector and transport packages for various pieces of functionality. The layered architecture is important as we separate the concerns of each component, reducing the complexity and providing pluggability.
Why Does The Client Matter?
The client is essentially abstracting away the details of providing resilient and fault tolerant communication between services. Making a call to another service seems fairly straight forward but there’s all sort of ways in which it could potentially fail.
Let’s start to walk through some of the functionality and how it helps.
Service Discovery
In a distributed system, instances of a service could be coming and going based on any number of reasons. Network partitions, machine failure, rescheduling, etc. We don’t really want to have to care about it this.
When making a call to another service, we do it by name and allow the client to use service discovery to resolve the name to a list of instances with their address and port. Services register with discovery on startup and deregister on shutdown.
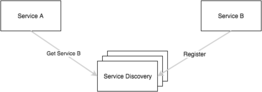
As we mentioned though, any number of issues can occur in a distributed system and service discovery is no exception. So we rely on battle tested distributed service discovery systems such as consul, etcd and zookeeper to store the information about services.
Each of these either use the Raft of Paxos network consensus algorithms which gives us consistency and partition tolerance from the CAP theorem. By running a cluster of 3 or 5 nodes, we can tolerate most system failures and get reliable service discovery for the client.
Node Selection
So now we can reliably resolve service names to a list of addresses. How do we actually select which one to call? This is where the go-micro Selector comes into play. It builds on the registry and provides load balancing strategies such as round robin or random hashing while also providing methods of filtering, caching and blacklisting failed nodes.
Here’s a cut down interface.
type Selector interface {
Select(service string, opts ...SelectOption) (Next, error)
Mark(service string, node *registry.Node, err error)
Reset(service string)
}
type Next func() (*registry.Node, error)
type Filter func([]*registry.Service) []*registry.Service
type Strategy func([]*registry.Service) Next
Balancing Strategies
The current strategies are fairly straight forward. When Select is called the Selector will retrieve the service from the Registry and create a Next function that encapsulates the pool of nodes using the default strategy or the one passed in as an option if overridden.
The client will call the Next function to retrieve the next node in the list based on the load balancing strategy and make the request. If the request fails and retries are set above 1, it will go through the same process, retrieving the next node to call.
There’s a variety of strategies that can be used here such as round robin, random hashing, leastconn, weighted, etc. Load balancing strategies are essential for distributing requests evenly across services.
Selection Caching
While its great to have a robust service discovery system it can be inefficient and costly to do a lookup on every request. If you imagine a large scale system in which every service is doing this, it can be quite easy to overload the discovery system. There may be cases in which it becomes completely unavailable.
To avoid this we can use a caching. Most discovery systems provide a way to listen for updates, normally known as a Watcher. Rather than polling discovery we wait for events to be sent to us. The go-micro Registry provides a Watch abstraction for this.
We’ve written a caching selector which maintains an in memory cache of services. On a cache miss it looks up discovery for the info, caches it and then uses this for subsequent requests. If watch events are received for services we know about then the cache will be updated accordingly.
Firstly, this drastically improves performance by removing the service lookup. It also provides some fault tolerance in the case of service discovery being down. We are a little paranoid though and the cache could go stale because of some failure scenario so nodes are TTLed appropriately.
Blacklisting Nodes
Next on the list, blacklisting. Notice the Selector interface has Mark and Reset methods. We can never really guarantee that healthy nodes are registered with discovery so something needs to be done about it.
Whenever a request is made we’ll keep track of the result. If a service instance fails multiple times we can essentially blacklist the node and filter it out the next time a Select request is made.
A node is blacklisted for a set period of time before being put back in the pool. It’s really critical that if a particular node of a service is failing we remove it from the list so that we can continue to serve successful requests without delay.
Timeouts & Retries
Adrian Cockroft has recently started to talk about the missing components from microservice architectures. One of the very interesting things that came up is classic timeout and retry strategies that lead to cascading failures. I implore you to go look at his slides here. I’ve linked directly to where it starts to cover timeouts and retries. Thanks to Adrian for letting me use the slides.
This slide really summarises the problem quite well.
What Adrian describes above is the common case in which a slow response can lead to a timeout then causing the client to retry. Since a request is actually a chain of requests downstream, this creates a whole new set of requests through the system while old work may still be going on. The misconfiguration can result in overloading services in the call chain and creating a failure scenario that’s difficult to recover from.
In a microservices world, we need to rethink the strategy around handling timeouts and retries. Adrian goes on to discuss potential solutions to this problem. One of which being timeout budgets and retrying against new nodes.
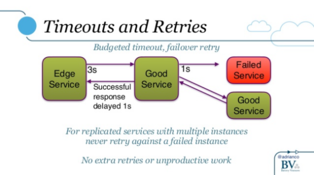
On the retries side, we’ve been doing this in Micro for a while. The Number of retries can be configured as an option to the Client. If a call fails the Client will retrieve a new node and attempt to make the request again.
The timeouts were something being considered more thoughtfully but actually started with the classic static timeout setting. It wasn’t until Adrian presented his thoughts that it became clear what the strategy should be.
Budgeted timouts are now built into Micro. Let’s run through how that works.
The first Caller sets the timeout, this usually happens at the edge. On every request in the chain the timeout is decreased to account for the amount of time that has passed. When zero time is left we stop processing any further requests or retries and return up the call stack.
As Adrian mentions, this is a great way to provide dynamic timeout budgeting and remove any unnecessary work occurring downstream.
Further to this, the next steps should really be to remove any kind of static timeouts. How services respond will differ based on environment, request load, etc. This should really be a dynamic SLA that’s changing based on its current state but something to be left for another day.
What About Connection Pooling?
Connection pooling is an important part of building scalable systems. We’ve very quickly seen the limitations posed without it. Usually leading to hitting file descriptor limits and port exhaustion.
There’s currently a PR in the works to add connection pooling to go-micro. Given the pluggable nature of Micro, it was important to address this a layer above the Transport so that any implementation, whether it be HTTP, NATS, RabbitMQ, etc, would benefit.
You might be thinking, well this is implementation specific, some transports may already support it. While this is true it’s not always guaranteed to work the same way across each transport. By addressing this specific problem a layer up, we reduce the complexity and needs of the transport itself.
What Else?
Those are some pretty useful things built in to go-micro, but what else?
I’m glad you asked… or well, I assume you’re asking…anyway.
Service Version Canarying?
We have it! It was actually discussed in a previous blog post on architecture and design patterns for microservices which you can check out here.
Services contain Name and Version as a pair in service discovery. When a service is retrieved from the registry, it’s nodes are grouped by version. The selector can then be leveraged to distribute traffic across the nodes of each version using various load balancing strategies.
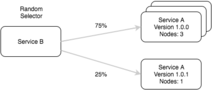
Why Is Canarying Important?
This is really quite useful when releasing new versions of a service and ensuring everything is functioning correctly before rolling out to the entire fleet. The new version can be deployed to a small pool of nodes with the client automatically distributing a percentage of traffic to the new service. In combination with an orchestration system such as Kubernetes you can canary the deployment with confidence and rollback if there’s any issues.
What About Filtering?
We have it! The selector is very powerful and includes the ability to pass in filters at time of selection to filter nodes. These can be passed in as Call Options to the client when making a request. Some existing filters can be found here for metadata, endpoint or version filtering.
Why Is Filtering Important?
You might have some functionality that only exists across a set of versions of services. Pinning the request flow between the services to those particular versions ensures you always hit the right services. This is great where multiple versions are running in the system at the same time.
The other useful use case is where you want route to services based on locality. By setting a datacenter label on each service you can apply a filter that will only return local nodes. Filtering based on metadata is pretty powerful and has much broader applications which we hope to hear more about from usage in the wild.
The Pluggable Architecture
One of the things that you’ll keep hearing over and over is the pluggable nature of Micro. This was something addressed in the design from day one. It was very important that Micro provide building blocks as opposed to a complete system. Something that works out of the box but can be enhanced.
Why Does Being Pluggable Matter?
Everyone will have different ideas about what it means to build distributed systems and we really want to provide a way for people to design the solutions they want to use. Not only that but there are robust battle tested tools out there which we can leverage rather than writing everything from scratch.
Technology is always evolving, new and better tools appear everyday. How do we avoid lock in? A pluggable architecture means we can use components today and switch them out tomorrow with minimal effort.
Plugins
Each of the features of go-micro are created as Go interfaces. By doing so and only referencing the interface, we can actually swap out the underlying implementations with minimal to zero code changes. In most cases a simple import statement and flag specified on the command line.
There are a number of plugins in the go-plugins repo on GitHub.
While go-micro provides some defaults such as consul for discovery and http for transport, you may want to use something different within your architecture or even implement your own plugins. We’ve already had community contributions with a Kubernetes registry plugin and Zookeeper registry in PR mode right now.
How do I use plugins?
Most of the time it’s as simple as this.
# Import the plugin
import _ "github.com/micro/go-plugins/registry/etcd"
go run main.go --registry=etcd --registry_address=10.0.0.1:2379
If you want to see more of it in action, check out the post on Micro on NATS.
Wrappers
What’s more, the Client and Server support the notion of middleware with something called Wrappers. By supporting middleware we can add pre and post hooks with additional functionality around request-response handling.
Middleware is a well understood concept and something used across thousands of libraries to date. You can immediately see the benefits in use cases such as circuit breaking, rate limiting, authentication, logging, tracing, etc.
# Client Wrappers
type Wrapper func(Client) Client
type StreamWrapper func(Streamer) Streamer
# Server Wrappers
type HandlerWrapper func(HandlerFunc) HandlerFunc
type SubscriberWrapper func(SubscriberFunc) SubscriberFunc
type StreamerWrapper func(Streamer) Streamer
How do I use Wrappers?
This is just as straight forward as plugins.
import (
"github.com/micro/go-micro"
"github.com/micro/go-plugins/wrapper/breaker/hystrix"
)
func main() {
service := micro.NewService(
micro.Name("myservice"),
micro.WrapClient(hystrix.NewClientWrapper()),
)
}
Easy right? We find many companies create their own layer on top of Micro to initialise most of the default wrappers they’re looking for so if any new wrappers need to be added it can all be done in one place.
Let’s look at a couple wrappers now for resiliency and fault tolerance.
Circuit Breaking
In an SOA or microservices world, a single request can actually result in a call to multiple services and in many cases, to dozens or more to gather the necessary information to return to the caller. In the successful case, this works quite well but if an issue occurs it can quickly descend into cascading failures which are difficult to recover from without resetting the entire system.
We partially solve some of these problems in the client with request retries and blacklisting nodes that have failed multiple times but at some point there may be a need to stop the client from even attempting to make the request.
This is where circuit breakers come into play.
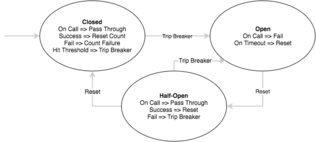
The concept of circuit breakers are straight forward. The execution of a function is wrapped or associated with a monitor of some kind which tracks failures. When the number of failures exceeds a certain threshold, the breaker is tripped and any further call attempts return an error without executing the wrapped function. After a timeout period the circuit is put into a half open state. If a single call fails in this state the breaker is once again tripped however if it succeeds we reset back to the normal state of a closed circuit.
While the internals of the Micro client have some fault tolerant features built in, we shouldn’t expect to be able to solve every problem. Using Wrappers in conjuction with existing circuit breaker implementations we can benefit greatly.
Rate Limiting
Wouldn’t it be nice if we could just serve all the requests in the world without breaking a sweat. Ah the dream. Well the real world doesn’t really work like that. Processing a query takes a certain period of time and given the limitations of resources there’s only so many requests we can actually serve.
At some point we need to think about limiting the number of requests we can either make or serve in parallel. This is where rate limiting comes into play. Without rate limiting it can be very easy to run into resource exhaustion or completely cripple the system and stop it from being able to serve any further requests. This is usually the basis for a great DDOS attack.
Everyone has heard of, used or maybe even implemented some form of rate limiting. There’s quite a few different rate limiting algorithms out there, one of which being the Leaky Bucket algorithm. We’re not going to go into the specifics of the algorithm here but it’s worth reading about.
Once again we can make use of Micro Wrappers and existing libraries to perform this function. An existing implementation can be found here.
A system we’re actually interested in seeing an implementation for is YouTube’s Doorman, a global distributed client side rate limiter. We’re looking for a community contribution for this, so please get in touch!
The Server Side
All of this has covered quite a lot about the client side features or use cases. What about the server side? The first thing to note is that Micro leverages the go-micro client for the API, CLI, Sidecar and so on. These benefits translate across the entire architecture from the edge down to the very last backend service. We still need to address some basics for the server though.
While on the client side, the registry is used to find services, the server side is where the registration actually occurs. When a an instance of a service comes up, it registers itself with the service discovery mechanism and deregisters when it exits gracefully. The keyword being being “gracefully”.

Dealing With Failure
In a distributed system we have to deal with failures, we need to be fault tolerant. The registry supports TTLs to expire or mark nodes as unhealthy based on whatever the underlying service discovery mechanism is e.g consul, etcd. While the service itself also supports re-registration. The combination of the two means the service node will re-register on a set interval while it’s healthy and the registry will expire the node if not refreshed. If the node fails for any reason and does not re-register, it will be removed from the registry.
This fault tolerant behaviour was not initially included as part of go-micro but we quickly saw from real world use that it was very easy to fill the registry with stale nodes because of panics and other failures which causes services to exit ungracefully.
The knock on effect was that the client would be left to deal with dozens if not hundreds of stale entries. While the client needs to be fault tolerant as well, we think this functionality eliminates a lot of issues upfront.
Adding Further Functionality
Another thing to note, as mentioned above, the server also provides the ability to use Wrappers or Middleware as its more commonly known. Which means we can use circuit breaking, rate limiting, and other features at this layer to control request flow, concurrency, etc.
The functionality of the server is purposely kept simple but pluggable so that features can be layered on top as required.
Clients vs Sidecars
Most of what’s being discussed here exists in the core go-micro library. While this is great for all the Go programmers everyone else may be wondering, how do I get all these benefits.
From the very beginning, Micro has included the concept of a Sidecar, a HTTP proxy with all the features of go-micro built in. So regardless of which language you’re building your applications with, you can benefit from all we’ve discussed above by using the Micro Sidecar.
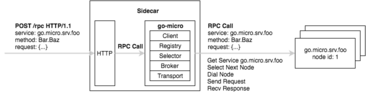
The sidecar pattern is nothing new. NetflixOSS has one called Prana which leverages the JVM based NetflixOSS stack. Buoyant have recently entered the game with an incredibly feature rich system called Linkerd, an RPC proxy that layers on top of Twitter’s Finagle library.
The Micro Sidecar uses the default go-micro Client. So if you want to add other functionality you can augment it very easily and rebuild. We’ll look to simplify this process much more in the future and provide a version prebuilt with all the nifty fault tolerant features.
Wait, There’s More
The blog post covers a lot about the core go-micro library and surrounding toolkit. These tools are a great start but they’re not enough. When you want to run at scale, when you want hundreds of microservices that serve millions of requests there’s still a lot more to be addressed.
The Platform
This is where the go-platform and platform come into play. Where micro addresses the fundamental building blocks, the platform goes a step further by addressing the requirements for running at scale. Authentication, distributed tracing, synchronization, healthcheck monitoring, etc, etc.
Distributed systems require a different set of tools for observability, consensus and coordinating fault tolerance, the micro platform looks to help with those needs. By providing a layered architecture we can build on the primitives defined by the core tools and enhance their functionality where needed.
It’s still early days but the hope is that the micro platform will solve a lot of the problems organisations have with building distributed systems platforms.
How Do I Use All These Tools?
As you can gather from the blog post, most of these features are built into the Micro toolkit. You can go check out the project on GitHub and get started writing fault tolerant Micro services almost instantly.
If you need help or have questions, come join the community on Slack. It’s very active and growing fast, with a broad range of users, from people hacking on side projects to companies already using Micro in production today.
Summary
Technology is rapidly evolving, cloud computing now gives us access to almost unlimited scale. Trying to keep up with the pace of change can be difficult and building scalable fault tolerant systems for the new world is still challenging.
But it doesn’t have to be this way. As a community we can help each other to adapt to this new environment and build products that will scale with our growing demands.
Micro looks to help in this journey by providing the tools to simplify building and managing distributed systems. Hopefully this blog post has helped demonstrate some of the ways we’re looking to do just that.
If you want to learn more about the services we offer or microservices, check out the blog, the website micro.mu or the github repo.
Follow us on Twitter at @MicroHQ or join the Slack community here.